

Most developers don’t think about their LLM routing layer until it’s 2 AM and a production system is down.
That’s precisely what happened in March 2026, except the crisis wasn’t a model outage. It was a supply chain attack. And the library at the centre of it was one that hundreds of engineering teams had quietly made the backbone of their entire AI infrastructure.
That library is LiteLLM. And if you’ve been building with AI in any serious capacity, there’s a good chance it’s already sitting between your code and every LLM you call.
What Is LiteLLM?
LiteLLM is an open-source AI Gateway and Python SDK that lets you call over 100 LLM providers, OpenAI, Anthropic, Google Gemini, AWS Bedrock, Azure, Cohere, Hugging Face, and more, through a single, unified interface built in the OpenAI format. One API. Any model. No rewriting your code when you switch providers.
It was launched on August 9, 2023, by Krrish Dholakia and Ishaan Jaffer under their San Francisco-based company BerriAI, backed by Y Combinator’s Winter 2023 batch. The founders, both AI infrastructure veterans, built LiteLLM to solve a frustration they lived personally: managing calls to different LLM providers meant writing sprawling, brittle if/else logic for every new model. They wanted a clean abstraction. So they built one.
Three years later, LiteLLM has 40,000+ GitHub stars, over 240 million Docker pulls, handles more than a billion LLM requests, and is trusted by companies including Netflix, Adobe, NASA, Stripe, and Nvidia. The team is 10 people. That ratio alone tells you something about how well the architecture scales.
How It Actually Works
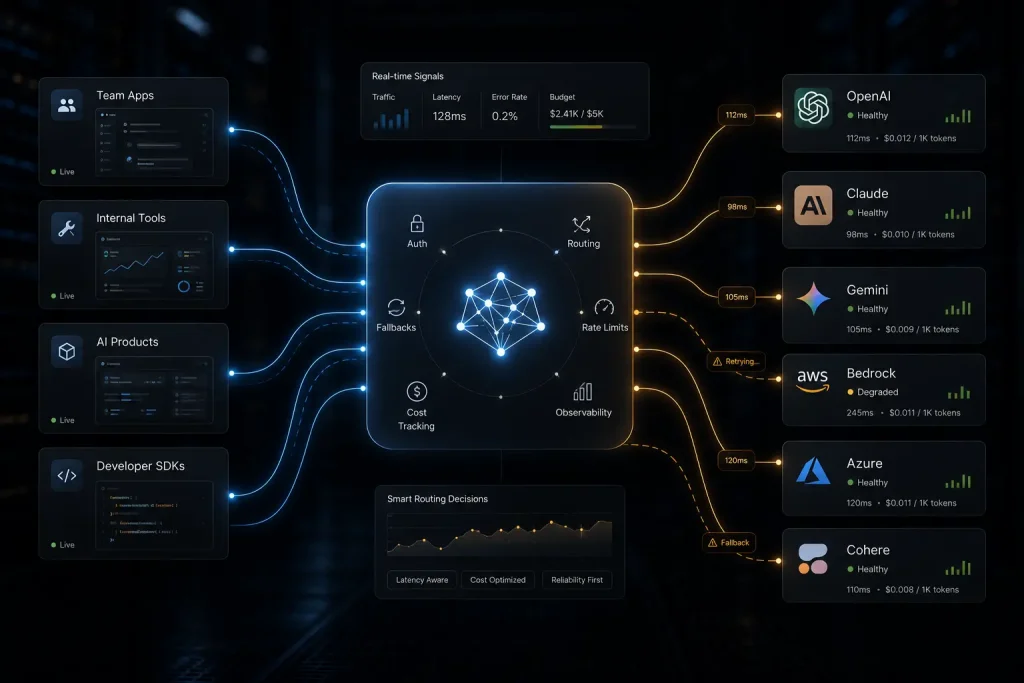
Think of LiteLLM as a translation layer between your application and the AI model zoo. Without it, calling GPT-5 looks different from calling Claude, which looks different from calling Gemini. Each provider has its own auth, request schema, error types, and response format. Managing that fragmentation at scale is genuinely painful.
LiteLLM removes that friction in two ways.
First, as a Python SDK, you import it directly into your code and call litellm.completion() with the provider and model name. LiteLLM translates your request into whatever format the provider requires, handles the response, and returns it in the familiar OpenAI structure. Swap providers by changing one string.
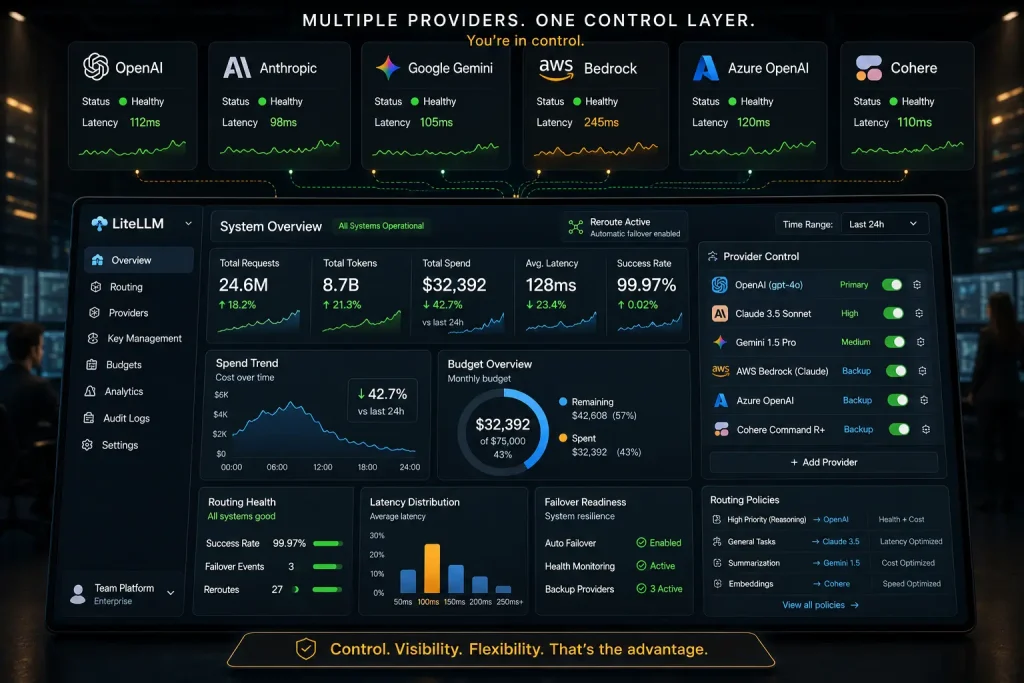
Second, as a Proxy Server (LLM Gateway): you deploy LiteLLM as a standalone FastAPI server, via Docker or Helm, and point all your apps at it. Your developers get virtual API keys, the gateway manages authentication to each upstream provider, and you get a central control plane for the entire organisation’s LLM usage.
The gateway mode is where the real power lives. It gives platform teams:
- Spend tracking: per-user, per-team, per-project, automatically calculated across OpenAI, Azure, Bedrock, and every other provider.
- Budgets and rate limits: set TPM/RPM caps per API key or team, with automatic enforcement.
- LLM fallbacks: if GPT-5 fails, route to Claude. If Claude is rate-limited, fall back to Gemini. Configured declaratively.
- Guardrails: input/output filtering, content safety, and integrations with tools like Akto for model-based detection.
- Observability: structured logging to S3, GCS, Langfuse, Langsmith, and OpenTelemetry-compatible destinations.
All of it accessible through an admin dashboard, and all of it deployable on-premises or in your own cloud.
How Real Teams Use It
Netflix uses LiteLLM to give their engineering teams Day 0 access to new LLMs the moment they’re released, without waiting for internal procurement, custom integrations, or security reviews on each new provider. The gateway handles authentication centrally; developers just pick a model.
For a company like Adobe or Stripe, the value is different but equally concrete: cost governance. When dozens of teams are calling different models at different rates, it becomes genuinely difficult to know who’s spending what, and even harder to enforce budgets. LiteLLM’s spend tracking and budget enforcement solves this at the infrastructure level, not by policy alone.
For startups building on top of multiple LLMs simultaneously, the fallback logic is often the killer feature. Model outages happen. Rate limits happen. Building redundancy into your LLM calls manually is tedious; configuring it in LiteLLM takes a few lines of YAML.
In 2026, LiteLLM also launched an Agent Platform alpha and added MCP (Model Context Protocol) support, positioning the gateway not just for raw LLM calls but as a control plane for the emerging world of multi-agent AI systems.
Infrastructure Before Models
The conversation around AI infrastructure has been almost entirely focused on the models themselves, like which is the fastest, which is cheapest, and which is smartest. But the real operational challenge for engineering teams isn’t choosing a model. It’s managing model access, costs, and reliability at scale.
LiteLLM represents a bet that the gateway layer will be as important as the models it routes to. And the evidence is accumulating. When the March 2026 supply chain attack hit, the security community’s response wasn’t “teams should use models directly.” It was a collective realisation about how much trust had been placed in this single layer, and a scramble to harden it properly.
By the time infrastructure becomes invisible, it has usually become essential.
“LiteLLM isn’t just another Python package. As an LLM gateway, it holds API keys for every provider it routes to. Compromising it means potentially exfiltrating credentials for an organization’s entire AI stack in one shot.” — Arthur AI Security Team.
The deeper insight is that AI infrastructure is converging on the same patterns as traditional software infrastructure. Databases got abstraction layers (ORMs). Cloud storage got unified SDKs. Now LLM access is getting its own gateway layer. That’s not a trend, it’s a maturation.
The Economics of Model Switching
Most teams adopt LiteLLM for technical reasons. They stay for financial ones.
Without a gateway, switching providers is an engineering project: new SDK, new auth, new error handling, new response parsing. Weeks of work, real regression risk. So teams absorb the price increases. They accept the rate limits. They stay put.
LiteLLM removes that friction almost entirely. Change a model string in a config file, and you’re routing to a different provider. That’s leverage, and providers know it.
Smarter teams go further. They never fully commit to one model. Expensive flagship models handle only what genuinely demands them. Cheaper alternatives absorb the rest: classification, summarisation, and low-stakes generation. Spend drops 40–70% without touching anything user-visible.
And when LiteLLM’s cost tracking attributes every token to a team, a feature, a project, suddenly AI ROI becomes a real conversation, not a monthly invoice and a guess.
The gateway isn’t just infrastructure. It’s a negotiating position.
Key Takeaways
- LiteLLM is an open-source AI Gateway and Python SDK for routing calls to 100+ LLMs through a single OpenAI-compatible interface.
- Founded in 2023 by Krrish Dholakia and Ishaan Jaffer (BerriAI, YC W23), now at $7M ARR with 40K+ GitHub stars and 1B+ requests served.
- Core enterprise features: spend tracking, virtual API keys, LLM fallbacks, guardrails, rate limiting, and an admin dashboard, all deployable on-prem.
- Used in production by Netflix, Adobe, NASA, Stripe, and Nvidia, primarily for Day 0 model access and cost governance.
- March 2026 supply chain attack compromised PyPI versions 1.82.7–1.82.8 for under five hours via a .pth file payload; source code on GitHub was never modified.
- Post-incident hardening includes CI/CD v2, cosign image signing, and SOC 2 Type 2 recertification.
- 2026 expansion includes Agent Platform support, MCP integration, Day 0 support for GPT-5.x and Claude models, and Gemini Embedding 2.
- Treat your LLM gateway as critical infrastructure, pin dependency versions, verify artefact hashes, and audit your .pth files.
Closing Thought
There’s a quiet irony at the center of LiteLLM’s story.
It was built to be invisible, a thin, frictionless layer that just works. And it succeeded so well that when attackers wanted to compromise AI infrastructure at scale, LiteLLM was the most efficient target they could find. Because everything flows through it.
That’s the paradox of good infrastructure. The better it gets at disappearing into the background, the more dangerous it becomes to ignore. Whether you’re evaluating LiteLLM for the first time or already running it in production, the question worth sitting with is this: Do you treat your AI gateway with the same rigour you’d give your database?
Because the teams that experienced March 2026 firsthand would tell you, you probably should.
