

There’s probably a phone somewhere in your home you haven’t touched in two years. Maybe it’s in a kitchen drawer, maybe it’s tucked into a box with dead chargers and tangled earbuds. The screen still lights up. The battery still holds a partial charge. And by every conventional measure, it’s useless.
It’s not.
That forgotten device is running a Snapdragon 845 or Apple A12 chip, the same silicon that, three years ago, was considered flagship hardware. And right now, in 2026, those chips are powerful enough to run a capable AI model. Locally. Privately. Without a single API call or a dollar of cloud spending.
The only thing missing was software small enough to fit.
That software finally exists.
Why Everyone Is Suddenly Paying Attention
For years, the story of AI has been a story of scale. Bigger models, bigger servers, bigger compute bills. OpenAI, Google, Anthropic, the names at the top of the stack, all run on data centres that consume as much electricity as small cities. And for a long time, the assumption was that serious AI had to live there, up in the cloud, inaccessible without an internet connection and a credit card.
But a parallel story has been building quietly. Researchers, open-source developers, and hardware companies have spent the last two years asking a different question: what’s the smallest model that can still do something genuinely useful?
The answer, arriving fast in 2026, is reshaping mobile technology from the ground up. Small language models (SLMs), compact AI systems with anywhere from 1 to 8 billion parameters, can now run in real time on consumer smartphones. Not just new flagship devices. Old ones too.
That changes things. Significantly.
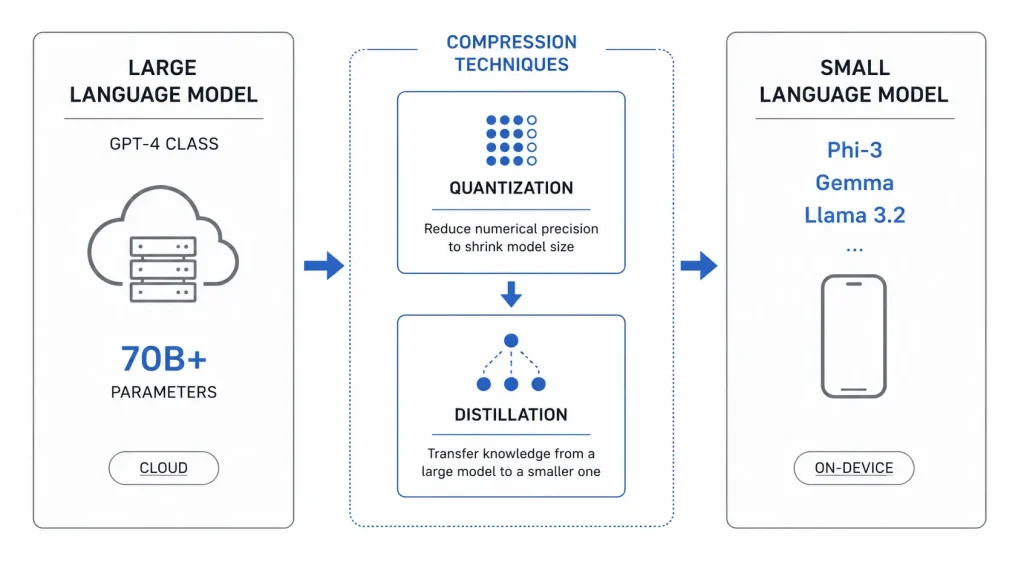
How It Actually Works
The Problem With Large Models
Standard large language models, GPT-4-class systems, carry hundreds of billions of parameters and require server-grade GPUs with tens of gigabytes of VRAM to run. A consumer phone has, at most, 12–16 GB of shared RAM and a mobile chip. Asking that hardware to run a 70-billion-parameter model is like asking a bicycle to haul freight.
But AI researchers found something useful: you can compress a model aggressively without destroying its usefulness. Two techniques made this possible at scale.
Quantization
Quantisation reduces the numerical precision used to store a model’s weights, from 16-bit or 32-bit floating point numbers down to 8-bit or even 4-bit integers. The result is dramatic: a model that originally needs 14 GB of memory might shrink to under 3 GB in a Q4_K_M quantised format, with minimal loss in output quality. It’s the AI equivalent of compressing a photograph; you lose some pixels, but the image remains recognisable.
Knowledge Distillation
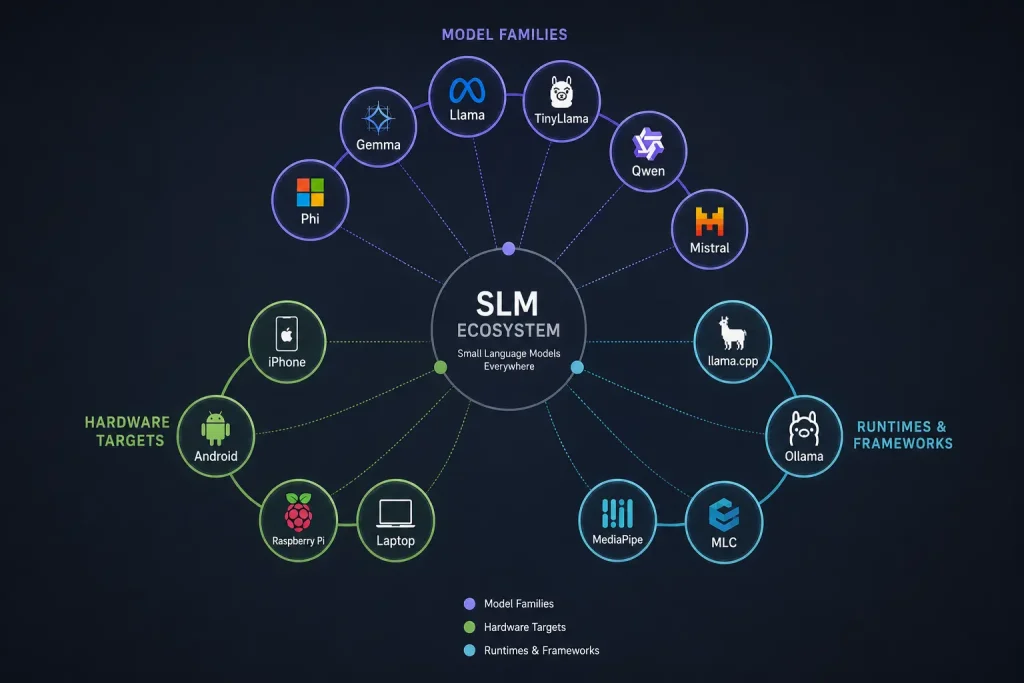
Knowledge distillation trains a small “student” model to replicate the behavior of a large “teacher” model. Microsoft’s Phi-3 and Phi-4 series, Google’s Gemma 2B and 3B, Meta’s Llama 3.2 1B and 3B, and the community-built TinyLlama are all products of this approach. These models absorb the learned reasoning patterns of much larger systems while fitting into a fraction of the memory.
The Hardware That Makes It Possible
On the device side, the key ingredient is the Neural Processing Unit (NPU), a dedicated silicon block optimised specifically for the matrix multiplication that powers AI inference. A couple of years ago, NPUs were a premium feature in flagship chips. Today, they’re standard in the Snapdragon 8 Gen 2, the Apple A16 and A17, and the MediaTek Dimensity 9000 series, chips that now live in three or four-year-old mid-to-flagship phones. The software layer completing this picture includes llama.cpp, an open-source inference engine written in C++ that compiles and runs quantised models directly on Android and iOS hardware, and Ollama, which layers a Docker-like simplicity on top, letting developers pull and run models with a single command.
Real-World Applications: What People Are Actually Building
The use cases are moving faster than most mainstream tech coverage has noticed. Droidclaw, an open-source project gaining serious traction in early 2026, turns old Android phones into always-on automation agents that operate through the actual phone UI, no API required. Unlike cloud-based automation tools that need enterprise app integrations, this approach works with any app on the device because it navigates the interface the way a human would.
Deutsche Telekom and Perplexity went further, building an AI phone from the hardware up, where pressing a physical button activates an on-device assistant that can book a taxi, make a dinner reservation, or translate speech in real time, all without unlocking the screen. The hardware and AI were designed together, not bolted on.
Researchers at Beijing University of Posts and Telecommunications found that SLMs purpose-built for a specific device’s hardware perform measurably better than large models fine-tuned for mobile use. The insight: design the model around the chip, not the other way around.
For developers, the practical workflow has simplified dramatically. A Llama 3.2 3B model quantised to Q4_K_M runs at a coherent, usable speed on any phone with a Snapdragon 855 or later, hardware that dates to 2019. Tools like Termux on Android allow llama.cpp to run without root access. The model downloads once, caches locally, and requires no further internet connection.
What Most Coverage Is Missing
“The shift from cloud LLMs to edge SLMs isn’t a performance optimisation. It’s a structural realignment of who controls intelligence, and where it lives“.
The mainstream narrative around AI on phones focuses on new devices, Apple Intelligence on the iPhone 16, Samsung’s Gemini integration, and Qualcomm’s Snapdragon AI benchmarks. That’s understandable. New hardware makes a cleaner copy.
But the more consequential story is about the billions of devices that already exist.
According to industry estimates, there are over 4 billion active smartphones in circulation globally, with hundreds of millions of “retired” devices sitting unused in drawers, boxes, and e-waste bins. A significant share of those devices carry chips capable of running 3B-class quantised models right now. Not next year. Now.
That installed base is, effectively, a distributed AI compute layer waiting to be activated. And unlike data centres, it’s already paid for. The energy cost of inference on a local device is orders of magnitude lower than a cloud API call routed through a GPU cluster. For developing regions where cloud API pricing is prohibitive, local on-device AI may be the only economically viable path to AI access.
There’s also a privacy dimension that matters more than it’s given credit for. When an AI model runs entirely on-device, your data never leaves your phone. No server logs. No training data harvesting. No subscription required. For health applications, legal research, personal journaling, or sensitive business tasks, this is not a minor feature, it’s the entire value proposition.
“On-device AI isn’t about matching cloud performance. It’s about reclaiming control.”
Limitations and Honest Trade-offs
This technology is real, but it is not magic. The constraints matter.
Performance ceiling: A 3B quantised model on a 2019 phone generates text at roughly 5–12 tokens per second, readable and functional, but noticeably slower than cloud-hosted models. Complex multi-step reasoning and nuanced creative writing still favour larger systems.
Context window limitations: Mobile-optimised models typically handle 2,000–8,000 token context windows. Long document analysis or extended conversations push against those boundaries quickly.
Thermal throttling: Sustained inference heats mobile chips. Most phones will throttle performance after five to ten minutes of continuous generation as a real constraint for agentic, always-on applications.
Storage requirements: Even a 3B model in 4-bit quantisation occupies 2–3 GB. Older phones with 32 or 64 GB of storage may find this impractical alongside existing apps and media.
Developer friction: While tools like llama.cpp and Ollama have lowered the barrier significantly, deploying and managing on-device models is still more technically demanding than calling an API endpoint. Mass-market consumer applications built on SLMs remain early-stage.
Key Takeaways
- Small language models (SLMs) running 1–8 billion parameters can now perform meaningful AI tasks on consumer-grade, older smartphone hardware.
- Quantisation and knowledge distillation are the core techniques, compressing model weights to 4- or 8-bit precision without catastrophic quality loss.
- The NPU (Neural Processing Unit) is the key hardware ingredient, now standard in chips dating to 2018–2019.
- Tools like llama.cpp, Ollama, and Termux make running a capable LLM on an Android phone achievable without rooting the device.
- On-device AI means zero cloud dependency: no API costs, no latency, no data leaving the device.
- Billions of existing “retired” devices represent untapped distributed compute that is already paid for and already in people’s hands.
- Practical limitations remain: thermal throttling, limited context windows, and slower generation speed versus cloud-hosted models.
Conclusion
The most powerful computer most people will ever own is probably already in a drawer somewhere in their home. Not because it’s the fastest or the newest, but because it’s paid for, it’s private, and it’s about to run AI.
The intelligence doesn’t need to live in the cloud to be useful. It never really did. What it needed was a model small enough to travel, and a patient enough to wait.
Both of those conditions are now met.
The question isn’t whether your old phone can become an AI device. It’s whether you’ll notice before you throw it away.
