

Uber’s CTO burned through his entire 2026 AI budget in a matter of weeks. A four-person startup spent $113,000 on AI in a single month. One documented debugging session consumed 21,000 input tokens to fix a one-character typo.
None of these people were being careless. They simply didn’t understand tokens.
The Unit Everything Runs On
Every prompt you type. Every response an AI generates. Every document you feed into a model. All of it is measured, processed, and billed in tokens.
A token is the smallest chunk of text an AI model processes. Not a word, not a character, but something in between. The practical rule of thumb: 1 token ≈ 4 characters ≈ 0.75 English words. A 750-word document is approximately 1,000 tokens. That sounds small. Until you realise that a single complex debugging session with a frontier model can consume over 500,000 tokens, and agentic coding workflows average between 1 and 3.5 million tokens per task.
This is why companies are getting surprised. The subscription price looked manageable. The token bill didn’t.
How Tokenization Actually Works
When you send a prompt to a model like GPT-5 or Claude, the text doesn’t arrive as words. It arrives as token IDs, the numerical representations of text chunks that the model’s vocabulary recognises. Common words become single tokens. Rare or technical words often get split across multiple tokens.
Code is denser than prose. CJK languages (Chinese, Japanese, Korean) use 2–3x more tokens per equivalent content than English. Low-resource languages can hit 10–15x more. A prompt that costs $0.10 in English might cost $1.00 in Japanese, same information, radically different bill.
Models charge separately for input tokens (what you send) and output tokens (what the model generates). Output tokens are universally more expensive, typically 3–5x the input price. Creating content costs more than reading it. That ratio reshapes everything about how you design prompts.
What Tokens Actually Cost in 2026
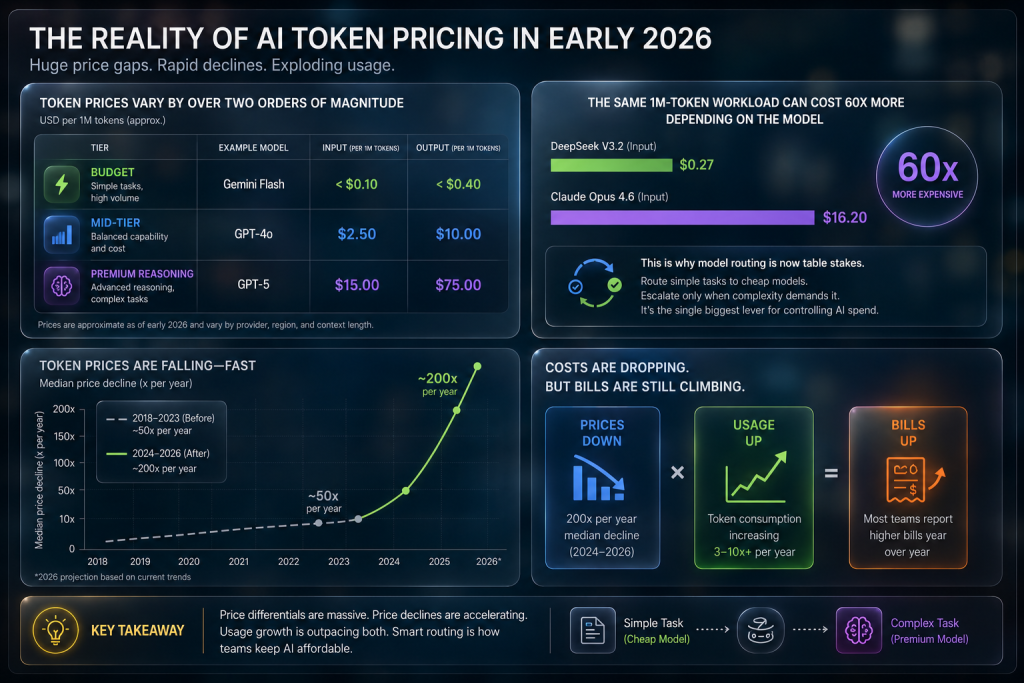
The price range is enormous. As of early 2026, budget models like Gemini Flash cost under $0.10 per million input tokens. Mid-tier models like GPT-4o sit at $2.50 input / $10 output per million. Premium reasoning models like GPT-5 hit $15 input / $75 output per million tokens.
Running the same 1M-token workload on Claude Opus 4.6 costs roughly 60x more than on DeepSeek V3.2. That differential is why model routing, sending simple tasks to cheap models and only escalating complex ones, has become standard practice among teams that actually manage AI costs.
Token prices have been falling fast. The median price decline hit 200x per year in 2024–2026, compared to 50x per year before that. Costs are dropping. But usage is growing faster, and the bills are still climbing.
The Context Window: Where Tokens Really Get Expensive
Every model has a context window, the total number of tokens it can hold in a single conversation or task. ChatGPT launched in 2022 with 8,192 tokens. By early 2026, five major models supported 1 million tokens. Meta’s Llama 4 Scout reaches 10 million.
Here’s what the marketing doesn’t say: effective context is 60–70% of the advertised maximum. A model claiming 200K tokens becomes unreliable around 130K. Researchers call the degradation that happens beyond the sweet spot ‘context rot’. The model starts confidently citing information that doesn’t exist while missing what’s actually in the middle of the document.
Every token in the context window is billed on every request. Long conversations don’t just feel expensive. They are. A session that started as a quick question and grew into a 40-message thread is feeding the entire conversation history back to the model each time you hit send.
What Companies Are Getting Wrong
This is where it gets uncomfortable. The mistakes aren’t technical. They’re about a gap between what companies think they’re managing and what they’re actually paying for.
- Sending flagship models to do budget tasks. 70–80% of enterprise AI tasks could be handled by cheaper models, but teams default to the most capable one out of habit.
- Ignoring context accumulation. Each message adds to context. Long agent sessions accumulate tokens exponentially. One wrong assumption early in a session contaminates everything that follows.
- No financial governance. Gartner’s March 2026 survey found that only 44% of organisations have adopted financial guardrails or AI FinOps practices to manage token spend, despite knowing costs are out of control.
- Assuming ‘more context = better output.’ Past the quality threshold, adding more tokens to a prompt often degrades quality while multiplying cost.
- Building agentic workflows without limits. Agentic AI that runs unsupervised can generate enormous token usage; one startup’s four-person team spent $113,000 in a single month this way.
Only 44% of organizations have adopted financial guardrails for AI token spend, despite knowing costs are out of control. The bill is arriving before the governance framework.
The Bigger Picture
Here’s what most people miss: tokens aren’t just a billing unit. They’re a design constraint. How you structure a prompt, how long you let a conversation run, which model you choose for which task, whether you use batch processing or a real-time API, all of it is token architecture. The teams winning at AI aren’t the ones with the biggest budgets. They’re the ones treating tokens the way good engineers treat memory: as a finite, valuable resource to be managed deliberately.
The shift is real. Token pricing is becoming the new compute cost, the infrastructure expense that defines whether an AI product is economically viable at scale. For some companies, it already exceeds their payroll. The organisations that understand this early are building cost-aware AI systems. The ones that don’t are discovering it the hard way, on a Tuesday, when the bill comes in.
Tokens aren’t just a billing unit. They’re a design constraint. The teams winning at AI treat tokens the way good engineers treat memory: as a finite, valuable resource.
What Tokens Can’t Fix

Understanding tokens solves the billing problem. It doesn’t solve the capability problem.
- Larger context windows don’t guarantee better reasoning. Quality degrades past certain thresholds regardless of how many tokens fit.
- Falling token prices don’t mean falling bills. Volume grows faster than costs fall, the net spend keeps climbing.
- Token optimisation can’t compensate for bad prompts. A concise, poorly-structured prompt wastes tokens differently than a verbose good one, but both produce bad results.
- Hallucinations cost tokens. AI hallucinations give confident, wrong answers, not just mislead users. With usage-based billing, inaccurate verbose outputs are also expensive.
Key Takeaways
- One token is roughly equal to four characters or about 0.75 words, which means a 750-word document usually comes out to around 1,000 tokens.
- Output tokens are significantly more expensive than input tokens, often costing three to five times more, so generating long responses increases costs quickly.
- Token pricing varies dramatically across models, ranging from about $0.08 to $75 per million tokens, making model selection one of the biggest factors in AI cost management.
- In practice, most models perform reliably only within about 60–70% of their advertised context window before “context rot” begins to reduce response quality.
- Agentic AI workflows can consume anywhere between one and 3.5 million tokens per task, which means costs can scale exponentially if usage limits are not controlled.
- Less than half of organizations currently have proper governance for token spending, leaving many companies without clear visibility into AI operational costs.
- Many cost-conscious teams now rely on model routing, using smaller and cheaper models for simple tasks while reserving premium models for more complex workloads.
The Question Worth Sitting With
There’s a version of the AI story where tokens are just an implementation detail, something the infrastructure handles and the business never needs to think about. That version doesn’t exist anymore.
In 2026, tokens are a strategy. They determine what’s affordable to build, what’s economical to run, and what’s viable at scale. The companies that understand their token footprint, not just their token bill, are building fundamentally different AI systems than the ones still thinking in subscriptions.
The real question isn’t how many tokens are we using? It’s: do we know what we’re buying with each one?
