

You type a question.
The AI responds in seconds.
It feels like it understands you.
But here’s what most people never realise:
It isn’t thinking, it’s predicting. And once you see how, everything changes.
AI models like LLaMA (Large Language Model Meta AI) are reshaping how we work, write, and search for information.
Yet for most people, the question of how AI actually processes data remains a black box, something left to engineers and researchers. It doesn’t have to be. The underlying mechanics of large language models are surprisingly logical, and understanding them takes no technical background whatsoever, just the right mental model.
This guide breaks down every stage of how LLaMA AI works: from ingesting raw training data to generating your response, one predicted word at a time.
It Learns by Reading at Massive Scale
Before you ever interact with an AI model, it has already gone through an intensive training phase, consuming hundreds of billions of words across:
- Books, academic papers, and long-form articles
- Websites, forums, and online discussions
- Code repositories and technical documentation
But the model doesn’t memorise any of this content.
Instead, it learns statistical patterns, which words tend to follow which, which ideas cluster together, and which sentence structures signal certain meanings.
Think of it like this: if you read millions of sentences beginning with “The weather today is…” you’d develop very strong intuitions about what comes next.
That’s exactly what LLaMA is doing, at a civilizational scale.
Language Gets Broken Into Tokens
When you send a message to an AI, it doesn’t process your words the way you wrote them.
First, the text is decomposed into smaller units called tokens, sub-word fragments that the model can work with efficiently.

This tokenisation step is critical. It allows the model to handle any language, any vocabulary, including words it has never seen before, by building them from familiar fragments. It also makes processing computationally tractable across enormous sequences of text. On average, one token equals roughly 4 characters, or ¾ of a word in English.
The Core Mechanic: Predicting the Next Token
Here is the single most important concept to understand about how large language models work:
“At every single step, the AI is asking one question: given everything before this point, what token comes next?”
This is powered by what researchers call the Transformer architecture, a design that lets the model weigh the importance of every previous token when making each prediction. You don’t need to know the technical details.
What matters is this: the model doesn’t have a fixed script. It recalculates probabilities dynamically for every single word.
This is why AI responses feel fluent and contextual, because they are, statistically speaking. The model has seen enough language to predict not just “what word fits here” but “what word fits here, given this entire conversation.”
Responses Are Generated Word by Word
When you ask LLaMA to explain something, it doesn’t retrieve a pre-written answer from a database. It generates the response dynamically, one token at a time.
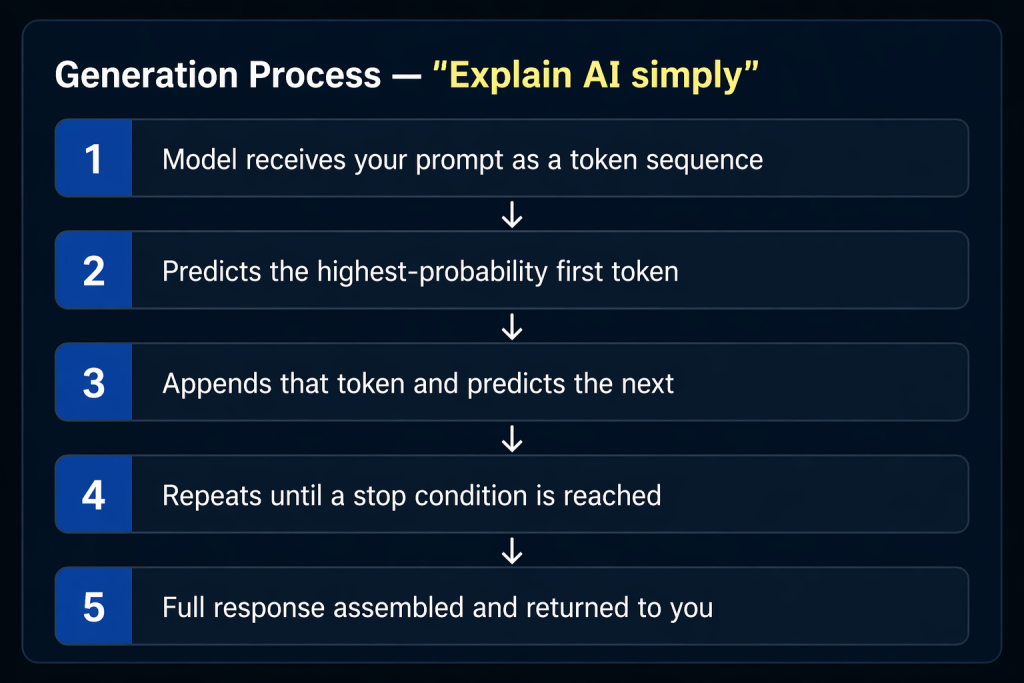
This sequential, autoregressive process is why AI responses stream in real-time, you’re literally watching the model generate, token by token, in front of your eyes.
It Only Uses What’s in the Current Context
Here’s something that surprises most people: AI models have no persistent memory between separate conversations.
Every interaction exists within a defined “context window”, think of it as the AI’s working memory for that session. The model can see everything in that window with perfect clarity. But once the session ends, that context is gone.
- It doesn’t remember your name from a previous chat
- It doesn’t build a profile of your preferences over time
- Each new conversation starts completely fresh
This has significant data privacy implications: your inputs are processed in the moment, not stored in the model’s “brain.” The model itself is a fixed set of mathematical weights, your conversation doesn’t change it.
How AI Uses External Data Without Storing It
Many enterprise AI deployments go one step further by injecting additional information directly into the context window before the model sees your question.
This technique, called Retrieval-Augmented Generation (RAG) , is how AI systems can appear to “know” about your company’s internal documents, recent news, or proprietary data.
The process works like this:
- Your question is received by the system
- Relevant documents are fetched from a database
- Those documents are prepended to your query in the context window
- The model answers using both your question and the retrieved context
Think of it as handing a research assistant a stack of relevant notes right before they answer your question. They use those notes, but they don’t keep them permanently.
The Mental Model That Ties It All Together
- Imagine a scholar who has read every book ever written, but remembers patterns, not pages.
- When you ask a question, they scan the patterns in their mind most relevant to your words.
- They construct an answer in real time, one phrase at a time, guided by what feels statistically right.
- They don’t look things up, they predict forward, using deep pattern recognition honed over millions of examples.
- Each new conversation is a blank slate; they walk in fresh every time.
Key Insight
AI doesn’t need to “understand” to be useful; it needs to be consistently accurate in prediction. That’s why it can feel brilliant and make confident errors in the same breath. The model doesn’t know what it doesn’t know. It only knows what patterns suggest.
Key Takeaways
- Training on patterns: LLaMA AI learns from billions of text examples, internalising statistical relationships between words and ideas, not facts stored as memories.
- Tokenisation: All input text is broken into sub-word fragments called tokens before the model processes it, enabling flexible and language-agnostic understanding.
- Next-token prediction: The entire generation process is built on one mechanism, predicting the most probable next token, over and over until the response is complete.
- No permanent memory: Your data is used within the active context window only. The model’s weights don’t change based on your conversation.
- Context injection: Enterprise systems can feed real-time data into the context window, enabling AI to answer questions about information far beyond its training cutoff.
- Confident errors are real: Because the model predicts rather than retrieves, it can generate plausible-sounding but factually wrong answers, a known limitation called “hallucination.”
Once You See It, You Can’t Unsee It
AI stops feeling like magic the moment you understand its prediction all the way down.
A very sophisticated, very fast, extraordinarily well-trained prediction system, but prediction nonetheless. That understanding matters practically. It explains why you should verify AI outputs for factual claims.
It explains why how you phrase a prompt changes the response so dramatically. And it explains why AI excels at pattern-heavy tasks, writing, summarising, coding, while struggling with tasks requiring true real-world grounding.
LLaMA and models like it represent a genuine leap forward in what machines can do with language. But they are tools built on mathematics, not minds built on experience.
If an AI doesn’t truly understand, but still performs so well, what does that say about how much of human communication is itself pattern-based?
The uncomfortable answer might be: more than we’d like to admit.
